How to Sample Networks Using Social Media APIs
If you were a social network analyst in the 1920s, 90% of your work would be to go around bugging people so that they could tell you whom they were friends with — we were, and still are, no fun at parties. Today, instead, we live in the land of plenty: 400 million new Instagram stories per day, 330 million monthly active users on Twitter, a gazillion Facebook profiles! What is there not to love? Well, to start, the fact that you do not have a download button, for very good and real reasons. That means that now 90% of your work is trying to figure out how to interface with these online media to sample the best possible representation of their social networks. So today I’m talking about how to sample a network via a social media API.
Let’s define our terms here. “Sampling a network” means to extract a part of it whose characteristics are as similar as possible to the entire structure. “API” is short for “Application Programming Interface.” It is the program in the server which interacts with the one you wrote to collect data. If you want to know the connections of user X, you ask the API and it will tell you. Most of the time. After a bit of nagging.

A good sample would look like the original network. A good sample like they wanted :’)
There are many approaches to sample networks, and many people have studied them to understand which one works best. But none of these studies actually made an experiment simulating their relationship with the actual API systems they have to work on. The comparisons made so far assume you can know all the connections of a user in one go, and that you can move to the other users as soon as you’re done exploring the current one. Sadly, the real world doesn’t remotely work that way. Thus we need to know how different API systems will influence different sampling methods. With Luca Rossi I wrote a paper about that, “Benchmarking API Costs of Network Sampling Strategies“, which I’ll present this month at the International Conference on Big Data.
An API system will put itself in the way of your noble sampling quest in three ways: (i) by returning only a maximum of n connections per request (i.e. by paginating the results), (ii) by making you wait a certain amount of time between requests, and (iii) by taking some time to respond (i.e. by having latency). The reason why considering the API hurdles is important is that they have a non-trivial relationship with your sampling method.
 To illustrate my point consider two API systems. The first system, A1, gives you 100 connections per request, but imposes you to wait two seconds between requests. The second system, A2, gives you only 10 connections per request, but allows you a request per second. A2 is a better system to get all users with fewer than 10 connections — because you are done with only one request and you get one user per second –, and A1 is a better system in all other cases — because you make far fewer requests, for instance only one for a node with 50 connections, while in A2 you’d need five requests.
To illustrate my point consider two API systems. The first system, A1, gives you 100 connections per request, but imposes you to wait two seconds between requests. The second system, A2, gives you only 10 connections per request, but allows you a request per second. A2 is a better system to get all users with fewer than 10 connections — because you are done with only one request and you get one user per second –, and A1 is a better system in all other cases — because you make far fewer requests, for instance only one for a node with 50 connections, while in A2 you’d need five requests.
It seems trivial that A1 is a better system than A2, because it gives you 50 connections per second instead of 10 (we’re ignoring latency here). However, that’s not necessarily the case. Real world networks are far from equal: there are a few superstars with millions of followers, while your average user only has a handful (but I’m catching up with you, Katy!). This means that there are way way way way way way way way more users with 10 or fewer connections than there are with more than 10. In the case represented by the figure, sampling the full network via A2 will actually take half as much time as via A1, even if theoretically we thought we were going to be five times slower.

How many users (y-axis) have this many connections (x-axis). The blue area is where A2 works best — one user per second — while the purple area is where A1 works best. But there are 492.5k users in the blue area (the Michele Coscias), and only 7.5k in the purple (the Katy Perrys)!
With Luca, I created a benchmarking system — which you can freely use — that allows you to simulate network sampling by letting you define:
- How the API works (pagination and wait time between requests);
- The sampling strategy (we investigate a few: BFS, DFS, Snowball, Random Walk and its variants, Forest Fire);
- What type of network you’re exploring (does it have communities? A power-law degree distribution? …);
- What characteristics of your network you want to preserve (degree distribution, homophily, …);
- How much time you can wait for your sample to be done.
So now we get to the point of the post where I tell you which sampling method is the very best and you should always use it and it will solve world peace and stuff. And that method is…
…none of them. Unfortunately we realized that, in the world of network sampling, there is no free lunch. The space of possible characteristics of interest, API systems, networks on which you work, and budget constraints is so vast that each sampling method is the best — or worst — in some combinations of these factors. We ran a bazillion tests, but none of them summarizes the results better than these two plots.
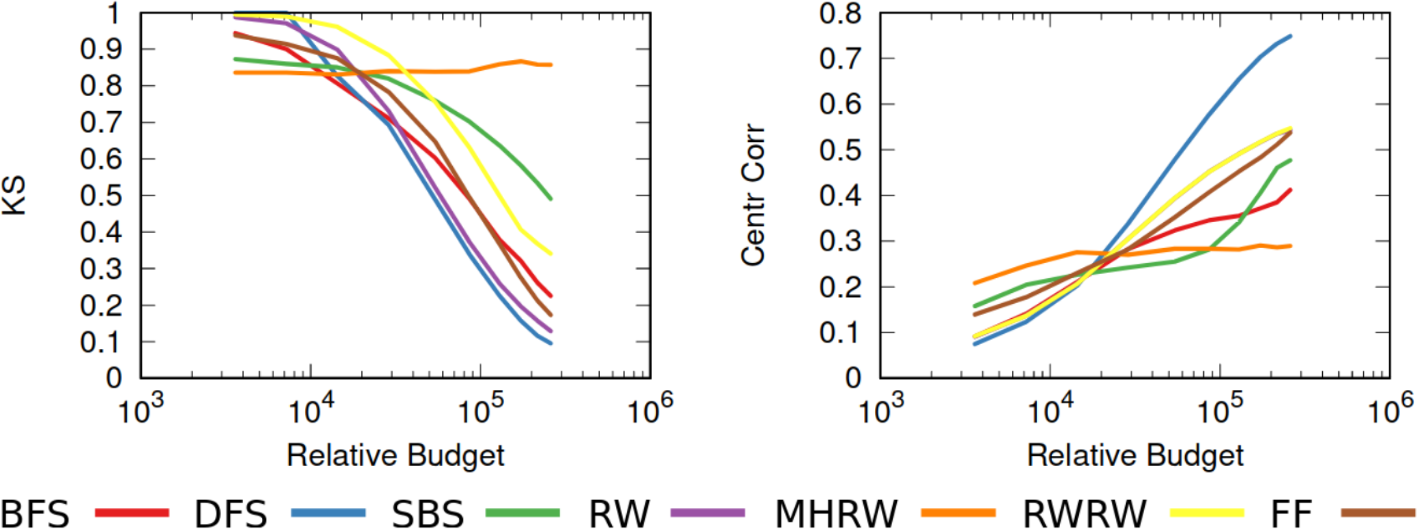
On the left you see how badly we get the degree distribution wrong (y-axis, lower is better) at different budget levels (x-axis, from left to right we increase the amount of time we spend sampling the network). If we don’t have much time, the best methods are a variant of Random Walks (MHRW) or Snowball sampling, while the worst method is DFS. But surprise surprise, if we have tons of time, DFS is the best method, and MHRW and Snowball are the worst. By a long margin. No free lunch. On the right we have another instance of the same problem: here we want to know how well we identify central nodes in the network (y-axis, higher is better). The difference at increasing budget levels is ridiculous: the rankings you get when you have a lot of time to sample are practically the opposite of the one you get when you’re in a hurry!
This means that you really need to be careful when you extract networks from social media. You cannot barge in and grab whatever you can, however you can. You need to know which characteristics of the network are important to you. You need to know what the underlying network might look like. You need to know how much time you have to sample the network, compared to its size. You need to know how their APIs work. Otherwise you’re going to run in circles in a very very mad world. And you thought that they had it worse in the 1920s.












{kind=link}