Nice Transaction Data Clustering Algorithm You Have There. It would be a Shame if Someone were to Misapply it.
I’m coming out of a long hiatus to write a quick post about a nice little paper I just put together with Riccardo Guidotti. The topic today is community discovery: the task of grouping nodes in a network because they connect to each other more strongly than with the other nodes in a network. No, wait, the actual topic is transactional data clustering: the task of grouping customers of a supermarket because they usually buy the same stuff. Wait what? What do these problems have to do with each other? Well, that’s what we concluded: the two things can be the same.
The title of the paper is “On the Equivalence between Community Discovery and Clustering” and it was accepted for publication at the GoodTechs conference in Pisa. The starting point of this journey was peculiar. Riccardo, being the smart cookie he is, published earlier this year a paper in the prestigious SIGKDD conference. In the paper, he and coauthors describe the Tx-means algorithm, that does exactly what I said before: it looks at the shopping carts of people, and figures out which ones are similar to each other. You can use it to give suggestions of items to buy and other nice applications. There is a three-minute video explaining the algorithm better than I can, which incidentally also shows that Riccardo has some serious acting chops, as a side of his research career:
The title of the paper is “Clustering Individual Transactional Data for Masses of Users” and you should check it out. So the question now is: how can I make all of this about me? Well, Riccardo wanted some help to break into the community discovery literature. So he asked my advice. My first advice was: don’t. Seriously, it’s a mess. He didn’t follow it. So the only option left was to help him out.
The main contribution of the paper is to propose one of the possible ways in which transactional data clustering can be interpreted as community discovery. The two tasks are known to be very similar in the literature, but there are many ways to map one onto the other, with no clear reason to prefer this or the other translation. In this paper, we show one of those translations, and some good reasons why it’s a good candidate. Now, the article itself looks like a five year old took a bunch of Greek letters from a bag and scattered them randomly on a piece of paper, so I’ll give you a better intuition for it.

The picture shows you transactional data. Each cart contains items. As the video points out, this type of data can also represent other things: a cart could be a user and the items could be the webpages she read. But we can go even more abstract than that. There is no reason why the items and the carts should be different entity types. A cart can contain… carts. We can define it as the list of carts it is related to, for any arbitrary relatedness criterion you’re free to choose (maybe it’s because they are cart-friends or something).
Once we do that, we can pivot our representation. Now it’s not transactional data any more: it is an edge list. Each node (the cart) lists the other nodes (cart-items) to which it connects. So this is a network — as shown below. What would it mean to find communities in this network? Well, it would mean — as I said at the beginning — to find groups of nodes that connect to each other. Or, in other words, group of carts that contain the same items (carts). Which is what Tx-means does.

This approach is a bit of a bastardization of community discovery because, if we apply it, then the community definition shifts from “densely connected nodes” to “similarly connected nodes.” But that’s a valid community definition — and that’s why community discovery is a mess — so we get a pass. It’s more or less the same thing I did on another working paper I’m sweating on, and so far only one person has called me out on that (thanks Adam), so I call it a success.
Why on Earth would we want to do this? Well, because Tx-means comes with some interesting advantages. First, let’s pitch it against some state of the art community discovery methods. In our experiments, Tx-means was the best at guessing the number of communities in networks of non-trivial size. This came without a big penalty in their Normalized Mutual Information — which measures how aligned the discovered communities are to the “real” communities as we gather them from metadata.
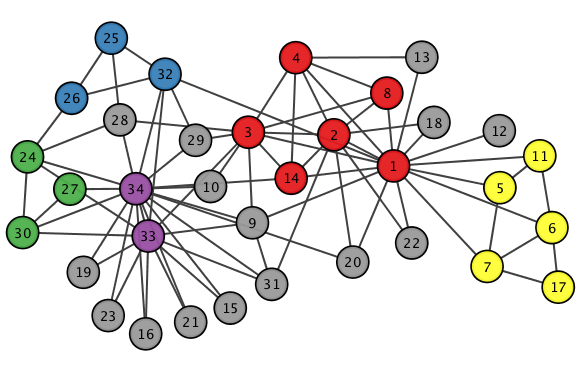
More importantly — as you saw in the video — Tx-means is able to extract “typical carts.” Translated into network lingo: with Tx-means you can extract the prototypical nodes of the community, or its most representative members. This has a number of applications if you are interested in, for instance, knowing who are the leaders, around which the nodes in the community coalesce. They are highlighted in colors in the picture above. You cannot really do this with Infomap, for instance.
So that’s the reason of this little exercise. Other transactional data clustering algorithms can use the same trick to go from carts to nodes, and therefore translate their features into the context of community discovery. Features that might be missing from the traditional algorithms we use to detect communities.
