After a year of dedicated effort, I’m glad to announce that the second version of my atlas for network science is finally out! Just like version one, the PDF is available free of charge both on arXiV and on the companion website, which also contains all the solutions to the exercises. If you’re a fan of physical books, you can buy it on Amazon.
Four years ago I published version one with the ambition of having a single text covering all I knew about network science in a coherent manner. The result was nice, but it had large margins of improvement. With this second edition, I aimed at improving the most egregious blind spots of the book.
The first one was about learning on graphs. Version one only had a small, confusing, imprecise chapter on this vast topic. That one chapter has blown up to four chapters, which now tackle shallow and deep learning more in depth. Of course none of those chapters get to the depth or sophistication of, say, Hamilton’s book, but I believe the value in having them in the Atlas is to show how much graph neural networks actually fit neatly into everything else from network science. They are not an extraneous body with esoteric methods: all GNNs do is adding some machine learning flavor to analyses we’ve been doing for decades, like using random walks to learn structural properties of the network.
Then, I decided to greatly expand on the background knowledge necessary to approach network science. This includes all the non-network techniques that will help you making sense of data. Again, what before was one background chapter became a whole book part with four chapters, covering probability theory, statistics, machine learning, and linear algebra.
The last major content addition is a chapter to deal with uncertain network data: what do you do when you’re unsure about the presence/absence of specific nodes/edges? There are more minor additions to the book, which are mentioned in the introduction.
Finally, last time no one yelled at me nearly enough for how tongue-in-cheek my introduction was. I took this as an encouragement to write an even more outlandish one. Fingers crossed someone will start a flame war on the social media du jour, and maybe the book goes viral and I get to retire with the $0.49 I make in profit per copy sold 🤞
Also bad news for those who want to stay healthy. All that added content means version two of the Atlas is even more back-breaking than version one:
The dinosaur is courtesy of my son.
For this book I had the additional help of a few more reviewers: Giovanni Puccetti, Matteo Magnani, Maria Astefanoaei, Daniele Cassese, and Paul Scherer. You’re very welcome to contact me if you find some more mistakes or if you have any grievances with the content — version one did ruffle some feathers.
So, if you want to become an expert on network science, a reminder: grab the free PDF on arXiV or on the website. And, if you really want to fuel my tiramisù addiction, you can always buy a physical copy on Amazon (or some other online seller). You could also go the Patreon route. I’ll see what I can cook in the next four years. Ta-ta.
Last year I was talking with a non-Italian, trying to convey to them how nearly the entirety of contemporary Italian music rests on the shoulders of Gianni Maroccolo — and the parts that don’t, should. In an attempt to find a way out of that conversation, they casually asked “wouldn’t it be cool to map out who collaborated with whom, to see whether it is true that Maroccolo is the Italian music Messiah?” That was very successful of them, because they triggered my network scientist brain: I stopped talking, and started thinking about a paper on mapping Italian music as a network and analyzing it.
I spent the best part of last year crawling the Wikipedia and Discogs pages of almost 2,500 Italian bands. I recorded, for each album they released, the lineup of the song players and producers. The result was a bipartite network, connecting artists to the bands they contributed to. I tried to have a broad temporal span, starting from the 1902 of Enrico Caruso — who can be considered the first Italian musician of note (hehe) releasing actual records — until a few of the 2024 records that were coming out as I was building the network — so the last couple of years’ coverage is spotty at best.
Then I could make two projections of this network. In the first, I connected bands together if they shared a statistically significant number of players over the years. I used my noise corrected backboning here, to account for potential missing data and spurious links.
This is a fascinating structure. It is dominated by temporal proximity, as one would expect — it’s difficult to share players if the bands existed a century apart. This makes a neat left-to-right gradient timeline on the network, which can be exploited to find eras in Italian music production by using my node attribute distance measure:
The temporal dimension: nodes are bands, connected by significant sharing of artists. The node color is the average year of a released record from the band.
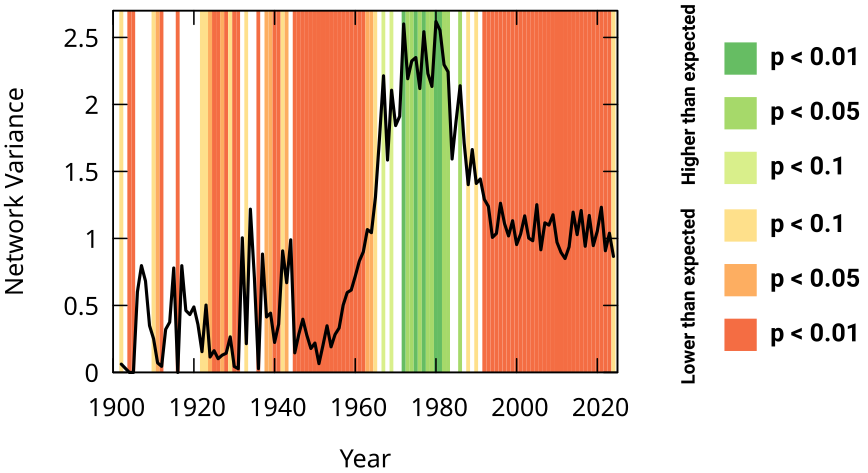
You can check the paper for the eras I found. By using network variance you can also figure out which years were the most dynamic, in terms of how structurally different the bands releasing music in those years were:
Network variance (y axis) over the years (x axis). High values in green show times of high dynamism, low values in red show times of structural concentration.
Here we discover that the most dynamic years in Italian music history were from the last half of the 1960s until the first half of the 1980s.
There is another force shaping this network: genre. The big three — pop, rock, electronic — create clear genre areas, with the smaller hip hop living at the intersection of them:
Just like with time, you can use the genre node attributes distances to find a genre clusters, through the lens of how they’re used in Italian music.
What about Maroccolo? To investigate his position, we need to look at the second projection of the artist-band bipartite network: the one where we connect artists because they play in the same bands. Unfortunately, it turns out that Maroccolo is not in the top ten most central nodes in this network. I checked the degree, closeness, and betweenness centralities. The only artist who was present in all three top ten rankings was Paolo Fresu, to whom I will hand over the crown of King of Italian Music.
Ideological polarization is the tendency of people to hold more extreme political opinions over time while being isolated from opposing points of view. It is not a situation we would like to get out of hand in our society: if people adopt mutually incompatible worldviews and cannot have a dialogue with those who disagree with them, bad things might happen — violence, for instance. Common wisdom among scientists and laymen alike is that, at least in the US, polarization is on the rise and social media is to blame. There’s a problem with this stance, though: we don’t really have a good measure to quantify ideological polarization.
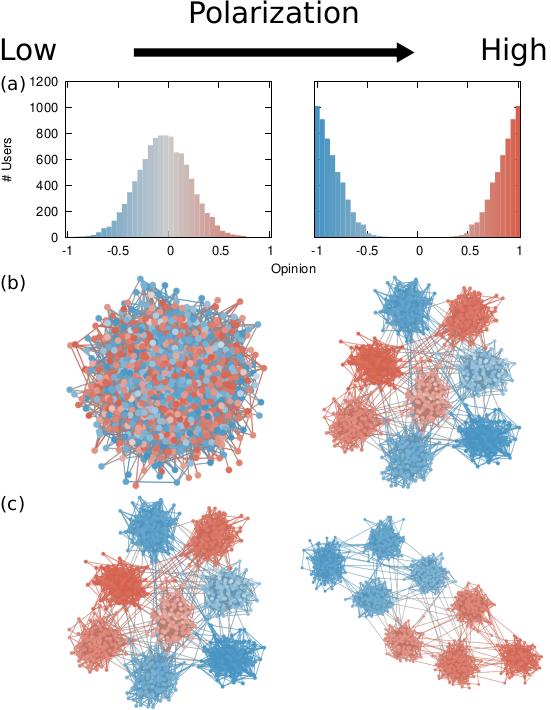
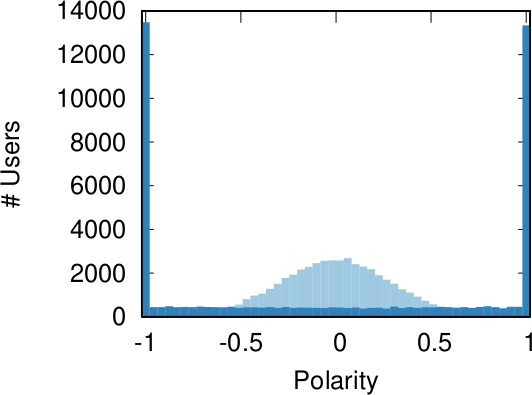
The components of our polarization definition, from top to bottom: (a) ideology, (b) dialogue, and (c) ideology-dialogue interplay. The color hue shows the opinion of a node, and its intensity is how strongly the opinion is held.
Our starting point was to stare really hard at the definition of ideological polarization I provided at the beginning of this post. The definition has two parts: stronger separation between opinions held by people and lower level of dialogue between them. If we look at the picture above we can see how these two parts might look. In the first row (a) we show how to quantify a divergence of opinion. Suppose each of us has an opinion from -1 (maximally liberal) to +1 (maximally conservative). The more people cluster in the middle the less polarization there is. But if everyone is at -1 or +1, then we’re in trouble.
The dialogue between parts can be represented as a network (second row, b). A network with no echo chambers has a high level of dialogue. As soon as communities of uniform opinions arise, it is more difficult for a person of a given opinion to hear the other side. This dialogue is doubly difficult if the communities themselves organize in the network as larger echo chambers (third row, c): if all communities talk to each other we have less polarization than if communities only engage with other communities that hold more similar opinions.
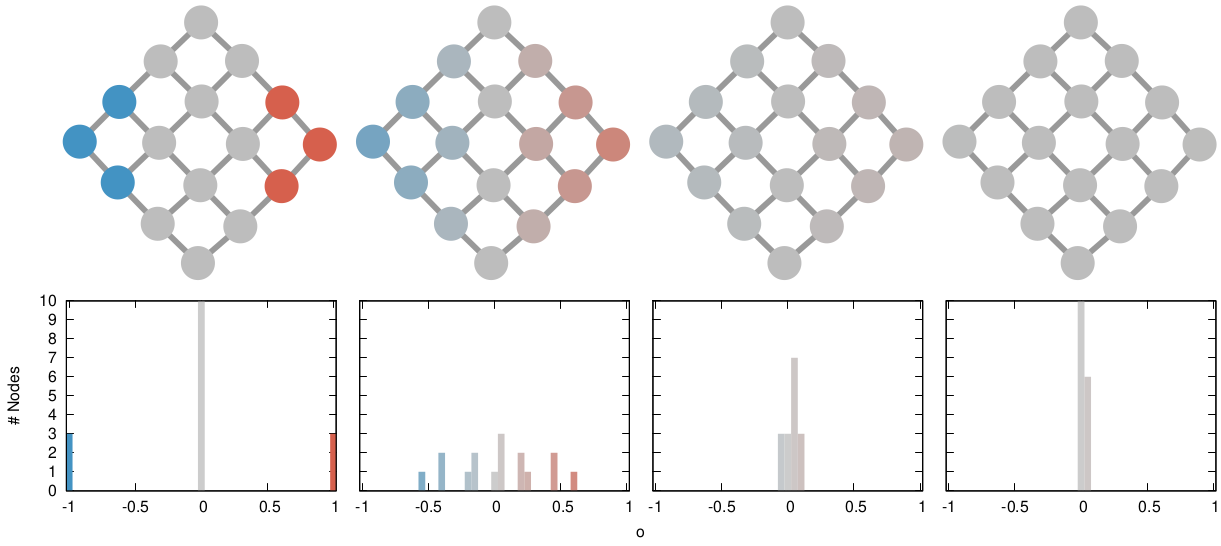
In this image, time flows from left to right: the first column is the initial condition with the node color proportional to its temperature, then we let heat flow through the edges. The plot on the second row shows the temperature distribution of the nodes.
The way we decided to approach the problem was to rely on the dark art spells of Karel, the Linear Algebra Wizard to simulate the process of opinion spreading. In practice, you can think the opinion value of each person to be a certain temperature, as the image above shows. Heat can flow through the connections of the network: if two nodes are at different temperatures they can exchange some heat per unit of time, until they reach an equilibrium. Eventually all nodes converge to the average temperature of the network and no heat can flow any longer.
The amount of time it takes to reach equilibrium is the level of polarization of the network. If we start from more similar opinions and no communities, it takes little to converge because there is no big temperature difference and heat can flow freely. If we have homogeneous communities at very different temperature levels it takes a lot to converge, because only a little heat can flow through the sparse connections between these groups. What I describe is a measure called “generalized Euclidean distance”, something I already wrote about.
Each node is a Twitter user reacting to debates and the election night. Networks on the top row, opinion distributions in the middle, polarization values at the bottom.
There are many measures scientists have used to quantify polarization. Approaches range from calculating homophily — the tendency of people to connect to the individuals who are most similar to them –, to using random walks, to simulating the spread of opinions as if they were infectious diseases. We find that all methods used so far are blind and/or insensitive to at least one of the parts of the definition of ideological polarization. We did… a lot of tests. The details are in the paper and I will skip them here so as not to transform this blog post into a snoozefest.
Once we were happy with a measure of ideological polarization, we could put it to work. The image above shows the levels of polarization on Twitter during the 2020 US presidential election. We can see that during the debates we had pretty high levels of polarization, with extreme opinions and clear communities. Election night was a bit calmer, due to the fact that a lot of users engaged with the factual information put out by the Associated Press about the results as they were coming out.
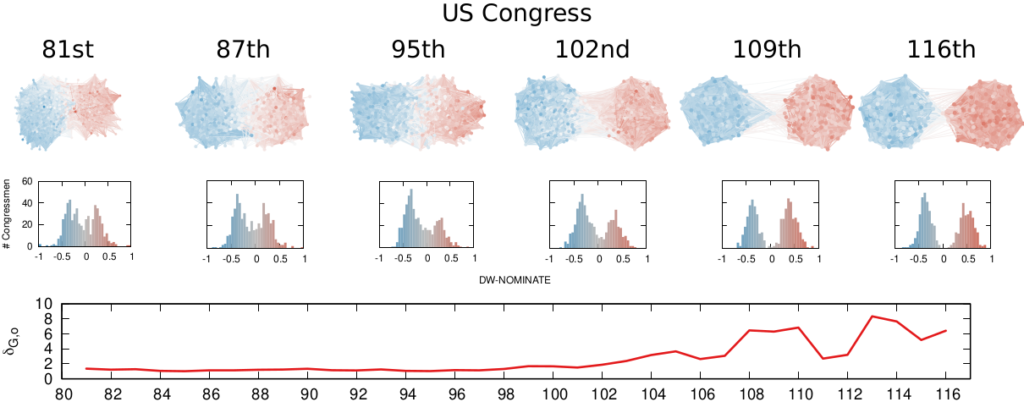
Each node is a congressman. One network per US Congress in the top row, DW-NOMINATE scores distributions in the middle row, and timeline of polarization levels in the bottom.
We are not limited to social media: we can apply our method to any scenario in which we can record the opinions of a set of people and their interactions. The image above shows the result for the US House of Representatives. Over time, congresspeople have drifted farther away in ideology and started voting across party lines less and less. The network connects two congresspeople if they co-voted on the same bill a significant number of times. The most polarized House in US history (until the 116th Congress) was the 113th, characterized by a debt-ceiling crisis following the full application of the Affordable Care Act (Obamacare), the 2014 Russo-Ukrainian conflict, strong debates about immigration reforms, and a controversial escalation of US military action in Syria and Iraq against ISIS.
Of course, our approach has its limitations. In general, it is difficult to compare two polarization scores from two systems if the networks are not built in the same way and the opinions are estimated using different measures. For instance, in our work, we cannot say that Twitter is more polarized than the US Congress (even though it has higher scores), because the edges represent different types of relations (interacting on Twitter vs co-voting on a bill) and the measures of opinions are different.
We feel that having this measure is a step in the right direction, because at least it is more accurate than anything we had so far. All the data and code necessary to verify our claims is available. Most importantly, the method to estimate ideological polarization is included. This means you can use it on your own networks to quantify just how fu**ed we are the healthiness of our current political debates.
We’ve all been on social media for far too long and it’s changed some of us. We started as starry-eyed enthusiasts: “surely the human race will be able recognize when I explain the One True Right Way of Doing Things” — whatever that might be — “so I’ll be nice to everyone as I’m helping them to reach the Light”. But now, when we read about hollow Earths or the Moon not existing for the 42nd time, we think “ugh, not this moron again”. And that’s the best-case scenario: we’ve seen examples of widespread harassment from people who, in principle, would propose philosophies of love and acceptance. It’s a curious effect, so it’s worthwhile to take a step back and ask ourselves: why does it happen?
This is what Camilla Westermann and I asked ourselves during her thesis project, which turned into the paper “A potential mechanism for low tolerance feedback loops in social media flagging systems,” published a couple of months ago on Plos One. We hypothesized there is a systemic issue: social media is structured in a way that leads people to quickly run out of tolerance. This is not a new idea: many people already pointed out that an indifferent algorithm sees “enragement” and thinks “engagement”, and thus it will actively recommend you the things most likely to make you mad, because anger will keep you on the platform.
Source: https://xkcd.com/386/
While likely true, this is an incomplete explanation. Profiting off radicalization doesn’t sound… nice? Thus it might be bad for business on the long run — if people with pitchforks start knocking at the shiny glass door of your social media behemoth. So, virtually all mainstream platforms have put systems into place to limit the spread of inflammatory content: moderation, flagging, and the like. So why isn’t it working? Why is online discourse apparently becoming worse and worse?
Our proposed answer is that these moderation systems — even if implemented in good faith — are the symptom of a haphazard understanding of the problem. To make our case we created a simple Agent-Based Model. In it, people read content shared by their friends and flag it when it is too far away from their worldview. This is regulated by a tolerance parameter: the higher your tolerance, the more ideological distance a news item requires to trigger your flagging finger.
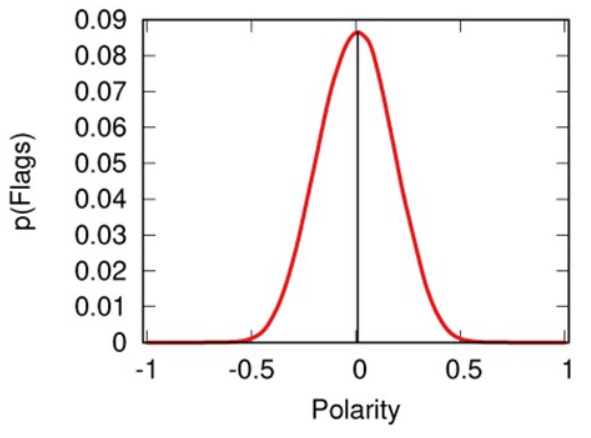
The proportion of flags (y axis) for a given opinion value (x axis). In this instance of the model, everyone has equally low tolerance (0.1).
This is a model I already talked about in the past and its results were pretty bleak. From the picture above you can see that neutral news sources get flagged the most. This is due to the characteristics of real-world social media — echo chambers, confirmation bias, and the like. In the end, we punish content producers for being moderate.
The thing I didn’t say that time was that the model only shows that pattern for low values in the tolerance parameter. For high tolerance, things are pretty ok. So, if everyone started as a starry-eyed optimist, how did we end up with *gestures in the general direction of Twitter*?
Our explanation is made of a simple ingredient: people think they’re right and want to convince others to behave accordingly because it’s Good — “go to church more!”; “use the correct pronouns!” –, so they do whatever they think will achieve that objective.
We started the model with the two sides having the same tolerance, set at very high levels, because we are incurable optimists. At each time step, one of the two sides will change their tolerance level. They will search for the tolerance level that will push news sources the most to their side — which, mind you, can also be a higher tolerance level, not necessarily a lower one.
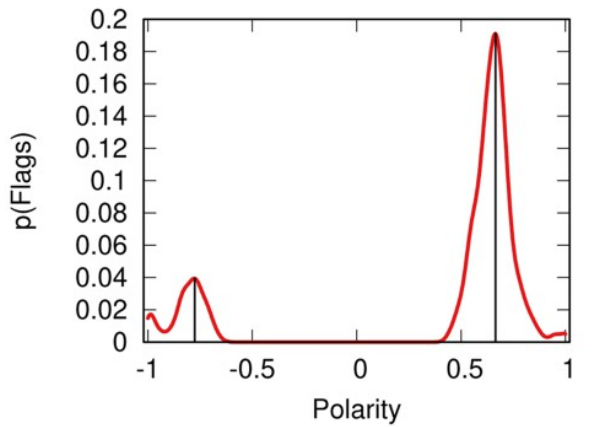
Same interpretation as the previous figure, but here the left side is less tolerant, so the right side gets flagged more. Tolerance is still quite high on both sides (0.8 vs 0.9).
The image above shows that, in the beginning, lowering tolerance is a winnning strategy. The news sources on the more tolerant side get flagged more by the people from the other, less tolerant, side. Since they don’t like being flagged, they are incentivized to find whatever opinion that will minimize the number of flags received — see this other previous work. This happens to pull them to the intolerant side. The problem is that, in our model, no one wants to be a sucker. “If they are attracting people to their side by being intolerant, why can’t I?” is the subconscious mantra we see happening. An intolerance death spiral kicks in, where both sides progressively push the other to even lower tolerance levels, because… it just works.
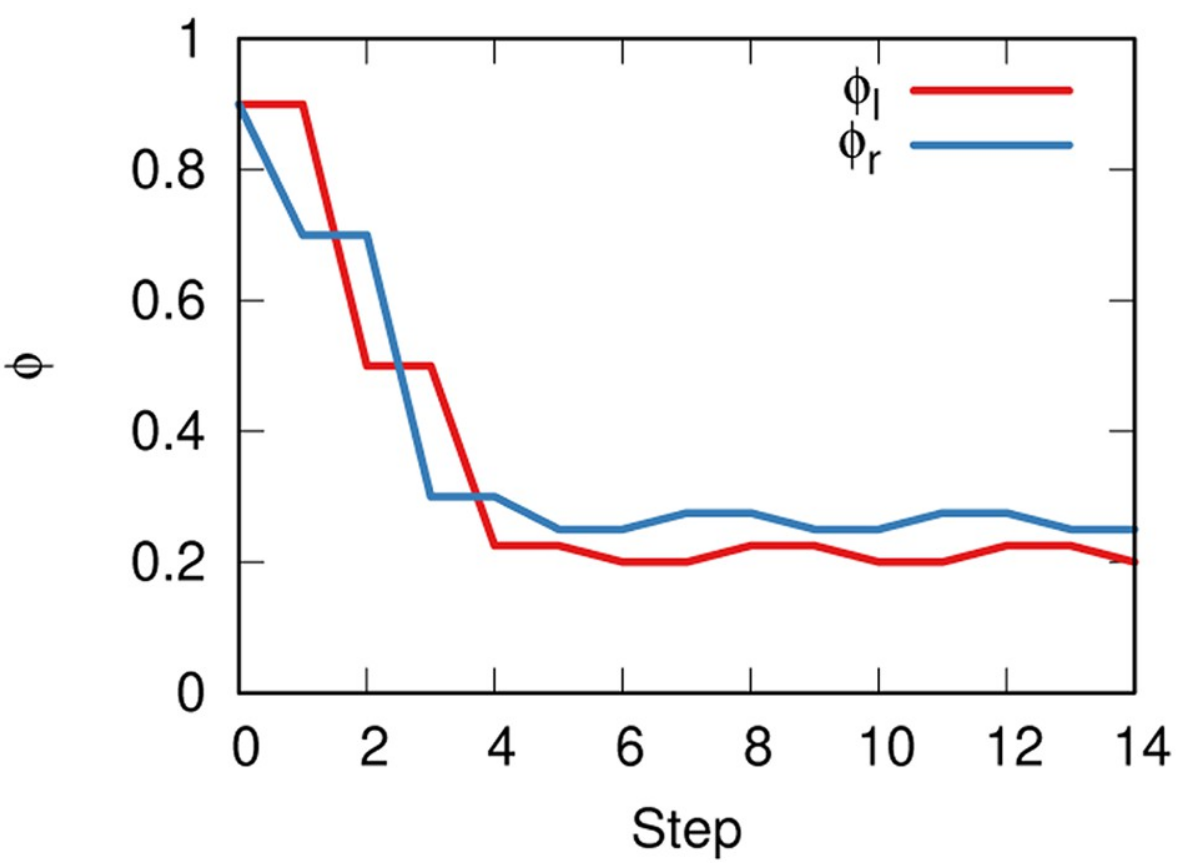
This happens until the system stabilizes to a relatively low — but non-zero — level of tolerance. Below a certain level, intolerance is so high it doesn’t attract any more. Too low tolerance only repulses, because people would flag you anyway, so what would be the point of moving closer to the intolerant side?
The line shows the tolerance level of two sides (y axis), red and blue, as it evolves when the model runs (x axis).
Of course, this is only the result of a simulation, so it should be taken with the usual boatload of grains of salt. The real world is a much more complex place, with many different dynamics, and humans aren’t blind optimizers of functions[citation needed]. However, it is a simulation using more realistic starting conditions than what social media flagging systems assume, and the low tolerance value for the parameter happens to be extremely close to our best guess estimation of what it is consistent with observed data. So ours might be a guess, but at least it’s decently educated.
What can we take from this research? If you own a social media platform, the advice would be not to implement poorly-thought-out flagging moderation systems: create models with more realistic assumptions (like ours) and use them to guide your solutions. Otherwise, you might be making the problem worse.
And if you’re a regular user? Well, maybe sometimes, being nice is better than making your side win. I’m looking forward to read on Twitter what some people think about this philosophy. I’m sure it will go great.
Look, I get it. Sometimes you really don’t want to get mired in a Facebook discussion with that uncle of yours who thinks that the moon doesn’t exist. It’s easier to block, unfriend, ignore, rather than engage. However, have you considered that avoiding conflicts might make things worse? This is a question Luca Rossi and I asked ourselves as a part of our research on polarization on social media. Part of the answer comes from an Agent Based Model (ABM) we have recently published on Plos One in the paper “How Minimizing Conflicts Could Lead to Polarization on Social Media: an Agent-Based Model Investigation.”
You sit on a throne of lies.
Specifically, we were interested in looking at how news sources react when they get attacked on social media with backlash and flagging. This is a followup to our previous paper, where we found — surprisingly — that this backlash and flagging is mostly directed at neutral and factual news sources. The reason why these sources are magnets for controversies is because their stories are widely read, and thus attract the ire of all sorts of quacks. Quackery, instead, is only read by quacks agreeing with it, and thus they don’t quack at it so much.
So now the question is: what does this negative attention from quacks do to a neutral news source? To answer the question we updated our ABM. In the original version, each news source and user had a fixed political position — a numerical value between -1 (extreme left) and +1 (extreme right), with 0 as perfect neutrality. In the new version, their position can change. People get attracted by similar points of view and repulsed by opinions that are too far from their position. For instance, a +1 user might get attracted if they read a +0.9 news item (moving to, say, a +0.95 position), but will be repulsed again if they read a -0.5 item next (moving back to, say, a +0.98 position).
Our starting assumption is that users and sources are mostly neutral. Here you can see the initial distributions of how many agents (y axis) have a given opinion (x axis). News sources in red and users in blue.
If a user is repulsed, they will also flag the news source. A news source doesn’t want to be flagged. A flag is a bad omen: too many flags and the news source might get banned by the social media platform, or be subject to big scary fact-checking banners. They might even — gasp! — make Mark Zuckerberg leak a tear. Social media are too important for news sources to let this happen. So they will try to avoid conflict. Since they know flags come from people with a different opinion from their own, the only thing they can do is to change their stance. The safest bet is to average the opinions of all their readers. Taking the average of their neighbors in most cases would lead to settle in the middle of thepolarity spectrum, but this is not guaranteed.
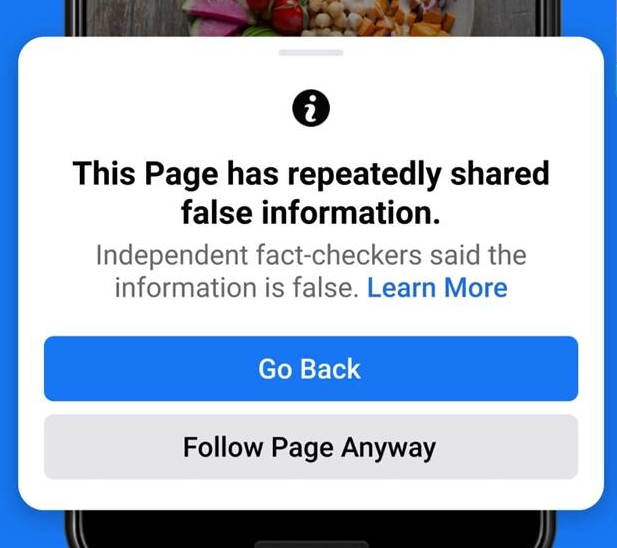
One example of the strategy social media have tried to use to combat misinformation online.
Four factors together create the rules of the game: how much users feel the need to share new articles on social media; how tolerant they are with diverse viewpoints; how much news sources will try to resist the pressure to change their spin; and how quickly users change their own opinion following what they read. Having an ABM allows you to run a lot of simulations and see what the effect of each of this aspect is on the final system.
We find that:
The more people share, the more news sources will be pushed away from neutrality and become partisan;
The less tolerant users are, the more they will increase polarization;
The resistance a news organization puts up against such a pressure is irrelevant to the final state of the system;
If users change their opinions easily, they will be attracted to the extreme ends of the polarity spectrum.
The difference between low tolerance (left) and high tolerance (right) in the opinion distributions of the users after the model has run for a while. Notice the extremist peaks in the left distribution.
Some of this is unsurprising — intolerance breeds polarization –, while other things might be worth looking at a second time. For instance, we think polarization is a bigger deal nowadays exactly because social media helps sharing in a way newspapers, radio, and television do not. Our results say that this oversharing exacerbates polarization. But a nagging question remains: is our ABM just a theoretical toy, or can it reproduce reality?
We think the latter is true, because we tested it against a real world Twitter network. We have a network topology of who talks with whom, and a polarity score for each user based on the news sources they cite in their tweets. The parameter combination that best reproduces real world data is this: high sharing, high opinion volatility, and low tolerance. Which in our model is the exact recipe for escalating conflict. And all of this just because news sources eschew conflict and don’t want to be flagged. Ouch.
This is what happens to the polarity distribution of the users when we try to fit our ABM model on real data from Twitter. Double ouch.
The same grains of salt that you should take our previous paper with also apply here. The model is based on assumptions, and thus it is only as good as those assumptions. Moreover, reality is more complicated than our ABM. For instance, we assume tolerance is uncorrelated with one own political opinion. But what if some political opinions tend to go together with being less tolerant of other points of view? And what if users don’t genuinely flag what they think is outrageous, but make a more strategic use of the flag button to advance their own agenda? These are questions we will explore in further developments of our work.
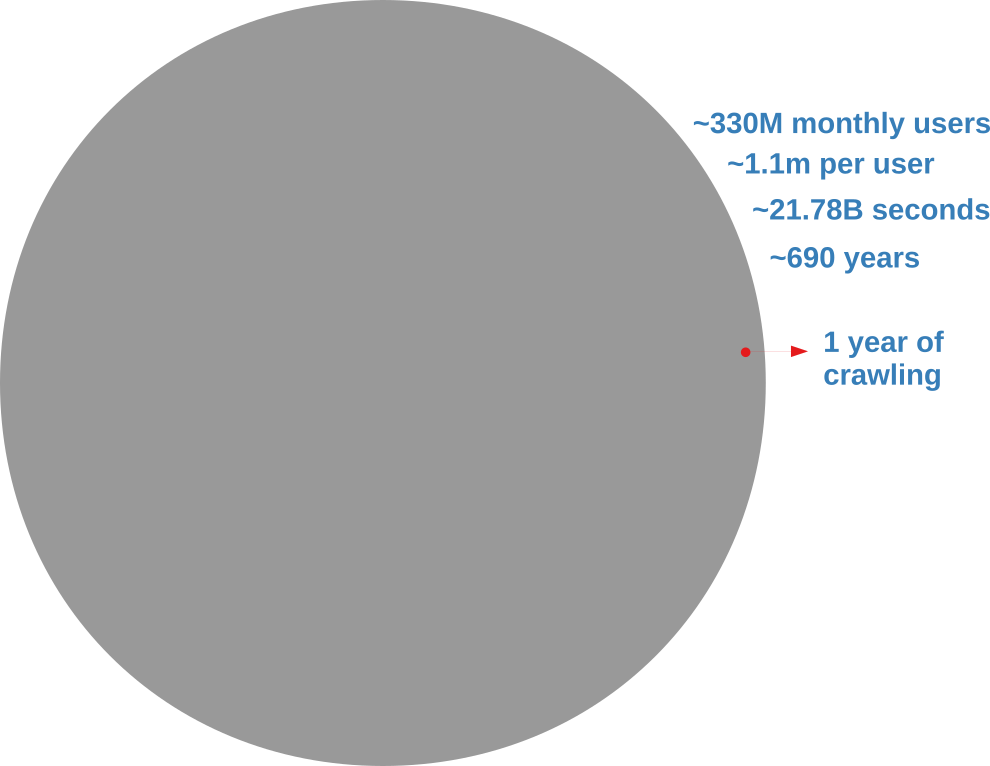
Analyzing an online social network is hard because there’s no “download” button to get the data. In the best case scenario, you have to query an API (Application Program Interface) system. You have to tell the API which user you want to see the connections of, and you can’t just ask for all users at the same time. With the current API rate limits, downloading the Twitter graph would take seven centuries, as the picture below explains.
The gray circle represents the totality of Twitter’s users. The red one is what you’d get with a continuous crawl of one year.
I don’t know about you, but I don’t have seven centuries to publish my papers. I want to become a famous scientist now. If you’re like me, you’re forced to extract only a sample. In this post, I’ll describe a network sampling algorithm that works with social media APIs to maximize the amount of information you get from your sample. The method has been published in the paper “Noise Corrected Sampling of Online Social Networks“, which recently appeared in the journal Transactions on Knowledge Discovery from Data.
My Noise Corrected sampling (NC) is a topological method. This means that you start from one (or more) user IDs that are known, and then you gather new user IDs from their friends, then you move on to the friends’ friends and so on, following the connections in the graph you’re sampling. This is the usual approach, because there is no way to know the user IDs beforehand — unless you have inside knowledge about how the social media platform works.
The underlying common question behind a topological sampler is: how do we pick the best user to explore next? Different samplers answer this question differently. A Random Walk sampler says: “Screw it! Thinking is too hard! I’m gonna get a random node from the friends of the currently explored node! Then, with the time I saved, I’m gonna get some ice cream.” The Metropolis-Hastings Random Walk — the nerd’s answer to the jock’s Random Walk — wants to preserve the degree distribution, so it penalizes high-degree nodes — since they’re more likely to be oversampled. Alternatively, we could use classical graph exploration techniques such as Depth-First and Breadth-First Search — and, again, you can enhance them so that you can preserve some properties of the network, for instance its clustering coefficient.
A random walk on a graph. It looks like a drunk going around. I don’t drink and sample, and neither should you.
My NC departs from all these approaches in a fundamental way. The thing they all have in common is that they don’t use information from the sample they have currently gathered. They only look at the potential next users and make a decision on whom to explore based on their characteristics alone. For instance Metropolis-Hastings Random Walk checks the user’s popularity in number of connections. NC, instead, looks at the entire collected sample and asks a straightforward question: “which of these next users is most likely to give me the most information about the whole structure, given what I explored so far?”
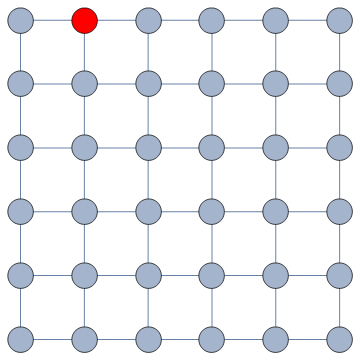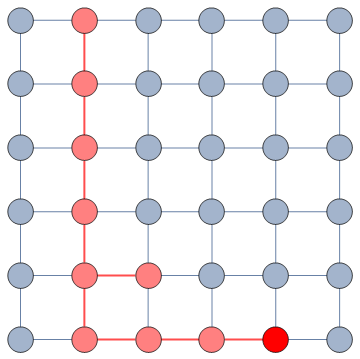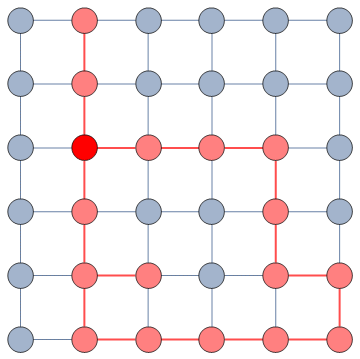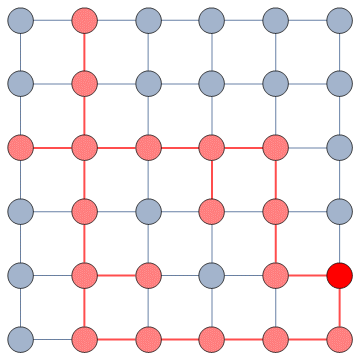
It does so with a Bayesian framework. The gory math is in the paper, but the underlying philosophy is that you can calculate a z-score for each edge of the network. It tells you how surprising it is that this edge is there. In probability theory, “surprise” is a good thing: it is directly related to how much information something gives you. Probability theorists are a bunch of jolly folks, always happy to discover jacks-in-a-box. If you always pick the most surprising edge in the network to explore the next user, you’re maximizing the amount of information you’re going to get back. The picture below unravels what this entails on a simple example.
In this example, the green nodes are explored, the blue nodes are known — because they’re friends of an explored node — but not explored yet. The red nodes are unknown.
The first figure (a) is the start of the process, where we have a network and we pick a random starting point, node 7. I use the edge thickness to show its z-score: we always follow the widest edge. Initially, you only pick a random edge, because all edges have the same z-score in a star. However, once I pick node 3, all z-scores change as we discover new edges (b). In this case, first we prioritize the star around node 7 (c), then we start following the path from node 3 until node 9 (d-e), then we explore the star around node 9 until there are no more nodes nor edges to discover in this toy network (f). Note how edges exhaust their surprise as you learn more about the neighborhoods of the nodes they connect.
Our toy example is an unweighted network, where all edges have the same weight, but this method thrives if you have information about how strong a connection is. The edge weight is additional information that can be taken into account to measure its surprise value. Under the hood, NC estimates the expected weight of an edge given the average edge weights of the two nodes it connects. In an unweighted network this is equivalent to the degree, because all edges have the same weight. But in a weighted network you actually have meaningful differences between nodes that tend to have strong/weak connections.
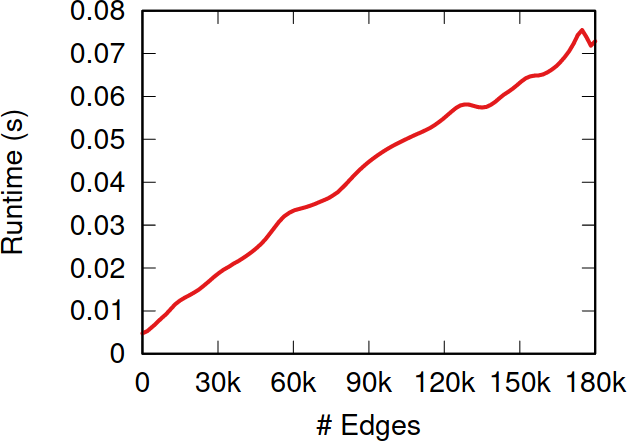
So, the million dollar question: how does NC fare when tested against the alternatives I presented before? The first worry you might have is that it takes too much time to calculate the z-scores. After all, to do so you need to look at the entire sampled network so far, while the other methods only look at a local neighborhood. NC is indeed slower than them—it has to be. But it doesn’t matter. The figure above shows how much time it takes to calculate the z-scores for more and more edges. Those runtimes (less than a tenth of a second) are puny when compared to the multi-second wait times due to the APIs’ rate limits — or even to simple network latency. After all, NC is a simplification of the Noise-Corrected Backbone algorithm I developed with Frank Neffke, and we showed in the original paper that it was pretty darn fast.
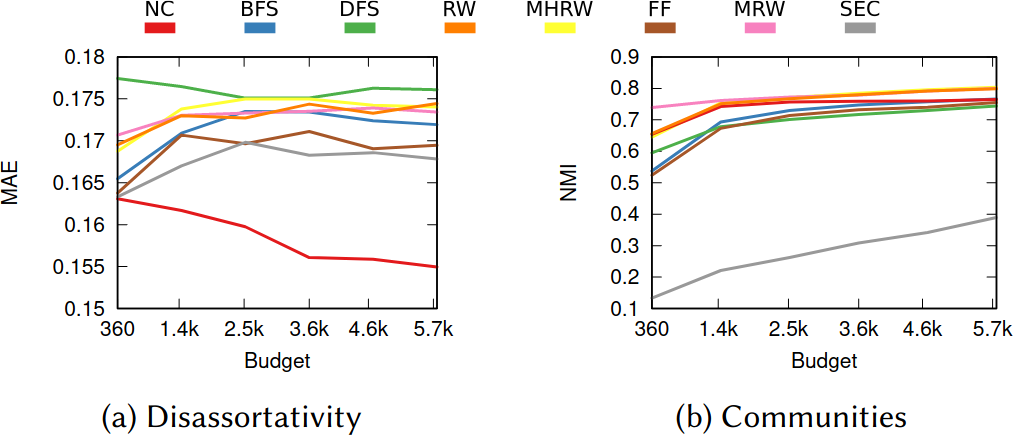
What about the quality of the samples? This is a question with a million answers, because it depends on what you want to do with the sample, besides what are the characteristics of the original graph and of the API system you’re wrestling against, and how much time you have to gather your sample. For instance, in the figure below we see that NC is the best method when you want to estimate the assortativity value of a disassortative attribute (think gender in a dating network), but it is a boring middle-of-the-pack method when you want to reconstruct the original communities of a network.
Left: the Mean Absolute Error between the sample’s and the original graph’s assortativity values (lower is better). Right: the Normalized Mutual Information between the sample’s and the original graph’s communities (higher is better). NC in red.
NC ranks between the 3rd and 4th position on average across a wide range of applications, network topologies, API systems, and budget levels. This is good because I test eight alternatives, thus the expectation is that NC will practically always be better than average. Among all eight methods tested, in fact, no other method has a better rank average. The second best method is Depth-First Search, which ranks 4th three out of four times, against NC’s one out of two.
I have shared some code allowing to replicate my results. If you speak Python better than you speak academiquese, you could use that code to infer how to implement an NC sampling strategy next time you need to download Twitter.
Last month I put out in public my Atlas for the Aspiring Network Scientist. The reaction to it was very pleasant and people contacted me with a number of corrections, opinions, and comments. I just uploaded to arXiV a version 1.1 of it, doing my best to address whatever could be addressed quickly. The PDF on the official website is also updated and, in fact, that link will always direct you to the most up-to-date version.
Corrections involve mostly some notation, a few references, and the like. One important thing I want to point out is my rephrasing/retraction of some humorous parts. I still stand by my decision of using humor, but not when it comes at the expense of the feeling of inclusiveness in the community. Science is a social process and everyone should feel welcome to it. Using language that opposes that aim is a net loss for society. One example is in the chapter about tools, where some ruvid humor didn’t paint the correct picture: these open source tools are fantastic gifts to the community and should be unequivocally celebrated. All remaining jokes are about the self-deprecation I feel every day from my inability to measure up to the awesome fellows behind these libraries/software.
One thing that was flagged to me but I couldn’t touch was references. There are just too many for me to check them all. I’m asking your help: if you find some issue with references (missing information, or things like editors as authors, etc), please write me flagging the specific reference with the issue: mcos@itu.dk.
I’m also glad to announce that you can buy a physical copy of the book, in case you need it handy for whatever reason. This is only v1, though, so all corrections mentioned above are not included. When v2 will come out, I’ll also make that available for physical purchase. The book was printed via IngramSpark, thus there’s a good chance you can find it for sale & shipping almost everywhere. For instance, it is available on Amazon or, if you’re in Denmark (where I live), on Saxo. You could even buy it on friggin’ Walmart.
The final object’s quality is… eh. Some of it is by design: I wanted this to be as accessible as possible. You’ll hardly find another 650+ color pages book in US Letter format for less than $40. Compromises needed to be made. However, most of the things making it a clearly amateurish product are my fault. Take a look at the left margin in the back cover:
Eww… Also, since I had to upload the cover separately, I didn’t remember to include a blank page. So the left pages are on the right and vice versa. Which makes page numbers practically invisible in the middle:
That said, if you ignore everything that makes this book ugly, it’s actually pretty nice:
Also, apologies to your backs, but this thing is hyuuuge. It’s as tall as a half-kilo pack of bucatini and twice as thick (packs of bucatini are a standard unit of measure in Italy):
Finally, I would love to give a shout out to everyone I interacted with after the book came out. Everyone was super nice and/or super helpful, most were both. I discovered many things I wasn’t aware of. One of them is NETfrix, a network science podcast by super cool fellow Asaf Shapira. The podcast has transcripts in English available here.
That’s it for now! Hopefully new research posts will follow soon.
In the past two years, I’ve been working on a textbook for the Network Analysis class I teach at ITU. I’m glad to say that the book is now of passable enough quality to be considered in version 1.0 and so I’m putting it out for anyone to read for free. It appeared on arXiV yesterday. It is available for download on its official website, which contains the solutions to the exercises in the book. Ladies and gentlemen, I present you The Atlas for the Aspiring Network Scientist.
As you might know, there are dozens of awesome network science books. I cannot link them all here, but they are cited in my atlas’ introduction. So why do we need a new one? To explain why the atlas is special, the best way is to talk about the defects of the book, rather than its strengths.
The first distinctive characteristic is that it aims at being broad, not deep. As the title suggests, I wanted this to be an atlas. An atlas is a pointer to the things you need to know, rather than a deep explanation of those things. In the book, I never get tired of pointing out the resources you need to actually understand the nitty-gritty details. When you stumble on a chapter on something you’re familiar with, you’ll probably have the feeling that you know so much more than me — which is true. However, that’s the price to pay if I want to include topics from the Hitting Time Matrix to the Kronecker graph model, from network measurement error to graph embedding techniques. No book I know includes all of these concepts.
The second issue derives from the first: this is a profoundly personal journey of eleven years through network science. No one can, in such a short time, master all the topics I include. Thus there’s an uneven balance: some methods are explained in detail because they’re part of my everyday work. And others are far from my area of expertise. Rather than hiding such a defect, the book wears it on its sleeve. I prefer to include everything I can even if I’m not an expert on it, because the first priority is to let people know that something exists. If I were to wait until I was an expert R programmer before advising you to use iGraph, the book would not exist. If I were to leave out iGraph because I’m not good at it, it would make the book weaker — and give the impression of dishonesty, like the classic Pythonist who ignores R because “it’s the opposing team”.
Finally, the book reads more like a post on this blog than an academic textbook. I use a colorful style and plenty of humor. This is partially as a result of the second point, since the humor is mostly self-deprecating about my limits — for instance, the stabs I take at R are intended as light-hearted jest. In general, I want to avoid being excessively dry and have the readers fall asleep at page 20. This is a risky move, because humor is subjective and heavily culture-dependent. People have been and will be put off by this. If you think I cross the line somewhere in the book, feel free to point that out and ask me to consider your concerns. If, instead, you think that humor in general has no place in academia, then I disagree, but there are plenty alternatives, so you can safely ignore my book.
Given all of the above, it is no surprise that the atlas is imperfect and many things need to be fixed. Trust me that the first draft was significantly worse in all respects. The credit for catching my mistakes goes to my peer reviewers. Every one of their comments was awesome, and every one of the remaining mistakes are only my fault for being unable to address the issues properly. Chief among the reviewers was Aaron Clauset, who read (almost) the entire thing. The others* still donated their time and expertise for free, some of them only asked me to highlight worthwhile charities such as TechWomen and Evidence Action in return.
Given all the errors that remain, consider this a v1.0 of a continuous effort. There are many things to improve: language, concepts, references, figures. Please contact me with any comments. The PDF on the website will reflect changes as soon as is humanely possible. Before I put v1.1 on arXiV, I’ll wait to have a critical mass of changes — I expect to have it maybe for mid to late February.
I also plan to have interactive figures on the website in the future. Version 1.0 was all financed using my research money and time. For the future, I will need some support to do this in my free time. If you feel like encouraging this effort, you can consider becoming a patron on Patreon. A print-on-demand version will be available soon (link will follow), so you could also consider ordering a physical copy — I’ll make 70 juicy cents of profit for every unit sold, because I’m a seasoned capitalist who really knows how to get his money’s worth for two years of labor.
I poured my heart in this. I really hope you’ll enjoy it.
The spread of misinformation — or “fake news” — is an existential threat for online social media like Facebook and Twitter. Since fake news has the power to influence elections, it has attracted legislative attention. And online social media don’t like legislative attention: Zuck wants to continue doing whatever he is doing. Thus, they need to somehow police content on their platforms before somebody else polices it for them. Unfortunately, the way they chose to do so actually backfires, as I show in “Distortions of Political Bias in Crowdsourced Misinformation Flagging“, a paper I just published with Luca Rossi in the Journal of the Royal Society Interface.
The way fact checking (doesn’t) work on online social media at the moment could be summarized as “semi-supervised crowdsourced flagging”. When a news item is shared on the platform, the system allows the readers to flag it for removal. The idea is that the users know when an item is a case of fake reporting, and will flag it when it is. Flags are then fed to a machine learning algorithm. The task of this algorithm is to filter out noise. Since there are millions of users on Facebook, practically every URL shared on the platform will be flagged at least once. After the algorithm pass, a minority of flagged content will be handed to experts, who will fact-check it*.
Sounds great, right? What could possibly go wrong? That’s what I defiantly asked Luca when he prodded me to look at the data of what was being passed to the expert fact checkers. As Buzzfeed would say, the next thing I saw shocked me. He showed me the top ten websites receiving the highest number of expert fact-checks in Italy — meaning that they received so many flags that they passed the algorithmic test. All major national Italian newspapers were there: Repubblica, Corriere, Sole 24 Ore. These ain’t your Infowars or your Breitbarts. They have clear leanings, but they are not extremist and they usually report genuinely, albeit selectively and with a spin. The fact-checkers did their job and duly found them not guilty.
So what gives? Why are most flags attached to mostly mild leaning, genuine reporting? Luca and I developed a model trying to explain this phenomenon. Our starting point was re-examining how the current system works: users see news, flag the ones that don’t pass the smell test, and those get checked. It’s the smell test that doesn’t pass the smell test. There are a few things impairing our noses: confirmation bias and social homophily.
Image from https://fs.blog/2017/05/confirmation-bias/
Confirmation bias means that a user will give an easier pass to a piece of news if the user and the news share the same ideological bias. Strongly red users will be more lenient with red fake news but might flag a more truthful blue news item, and vice versa. Social homophily means that people tend to be friends with people with a similar ideological leaning. Red people have red friends, blue people have blue friends. It’s homophily that gives birth to filter bubbles and echo chambers.
So how do these two things cause flags to go to popular neutral sources? The idea is that extremism is rare — otherwise it wouldn’t be extreme. Thus, most news organizations and users are neutral. Moreover, neutral news items will reach every part of the social network. They are produced by the most popular organizations and, on average, any neutral user reading them has a certain likelihood to reshare them to their friends, which may include more extreme users. On the other hand, extreme content is rare and is limited to its echo chambers.
Image from “MIS2: Misinformation and Misbehavior Mining on the Web”
This means that neutral content can reach the red and blue bubbles, but that extreme red and blue content will not get out of those same bubbles. An extreme red/blue factional person will flag the neutral content: it is too far from their worldview. But they will never flag the content of opposite color, because they will never see it. The fraction of neutral users seeing and flagging the extreme content is far too low to compensate.
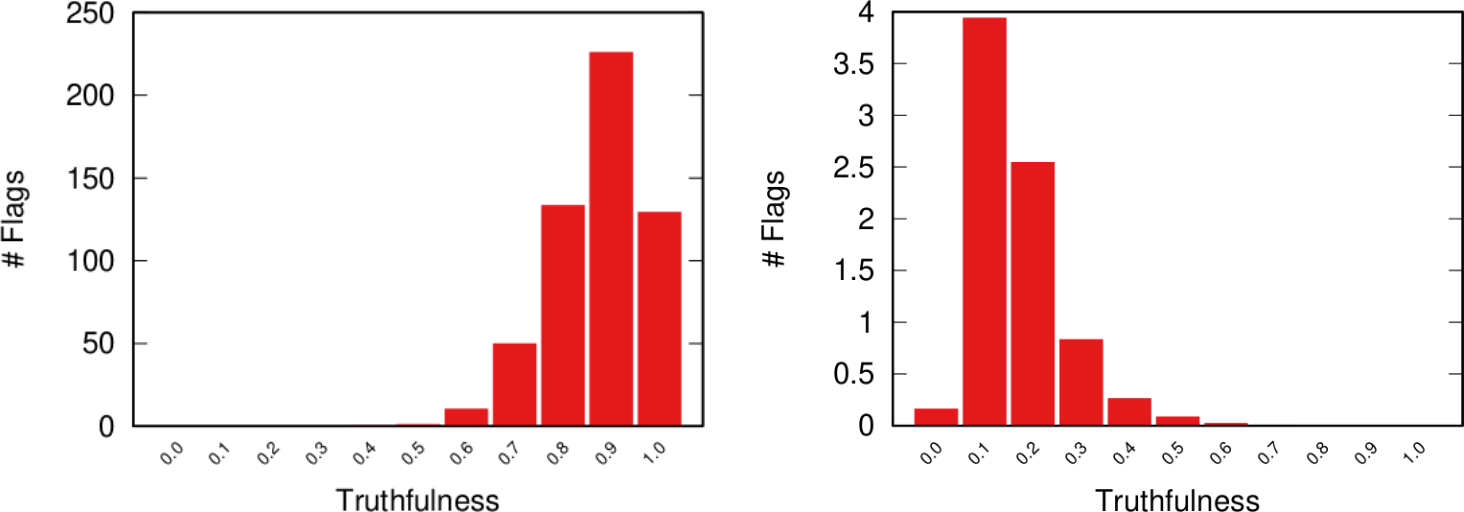
Luca and I built two models. The first has the right ingredients: it takes into account homophily and confirmation bias and it is able to exactly reproduce the flagging patterns we see in real world data. The model confirms that it is the most neutral and most truthful news items that get flagged the most (see image below, to the left). The second model, instead, ignores these elements, just like the current flagging systems. This second model tells us that, if we lived in a perfect world where people objectively evaluate truthfulness without considering their own biased worldview, then only the most fake content would be flagged (see image below, to the right). Sadly, we don’t live in such a world, as the model cannot reproduce the patterns we observe. Sorry, the kumbaya choir practice is to be rescheduled to an unspecified date (also, with COVID still around, it wasn’t a great idea to begin with).
From our paper: the number of flags (y axis) per value of news “truthfulness” (x axis) in the model accounting for factionalism (left) and not accounting for factionalism (right). Most flags go to highly truthful news when accounting for factionalism.
Where to go from here is open to different interpretations. One option is to try and engineer a better flagging mechanism that can take this factionalism into account. Another option would be to give up altogether: if it’s true that the real extreme fake content doesn’t get out of the echo chamber, why bother policing it? The people consuming it wouldn’t believe you anyway. Luca and I will continue exploring the consequences of the current flagging mechanisms. Our model isn’t perfect and requires further tuning. So stay tuned for more research!
* Note that users can flag items for multiple reasons (violence, pornography, etc). This sort of outsourcing is done only for fact-checking, as far as I know.
A moral imperative that wealthy communities have — in my opinion — is to ensure economic convergence: to help the poorer economies to have a stronger economic growth so that everyone is lifted out of poverty*. There is a lot of debate on whether economic convergence is actually happening (some say yes, others no) — and, if so, at which scale (global, national, regional?). In my little contribution to the question I show that — if convergence happens — it is not via traditional institutional channels, but via participation in the global social network. Which is terrible news in these days, since we’re experiencing an unprecedented collapse in this web of relations due to the COVID-19 pandemic.
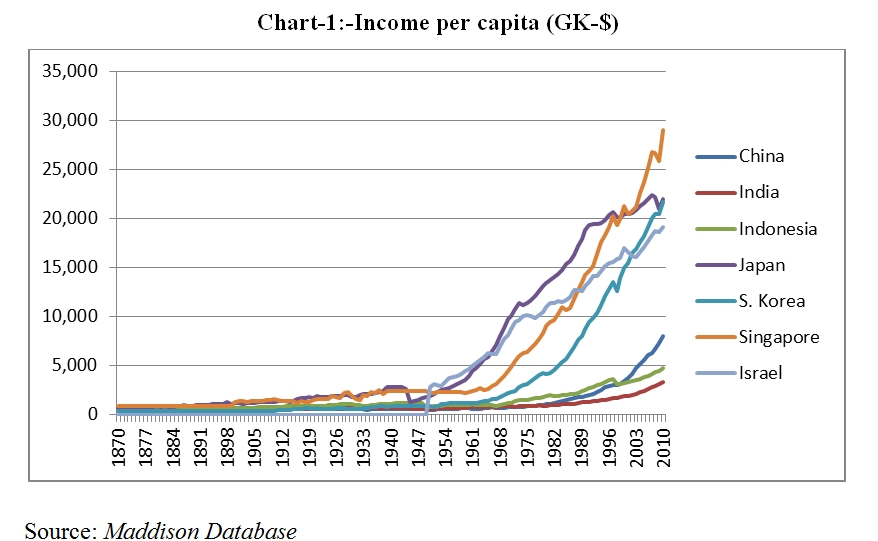
An example of economic divergence: some countries like Singapore are now 6X richer than other countries that had a comparable level of income in the late 1800. Image from EconoTimes.
The idea is simple: we want to know whether economic convergence happens in Colombia. If it does, we want to show that its driving force is the participation in social networks. In other words, economic growth is a matter of connecting skillful people with people possessing capital. We need to make sure we’re not confusing our “social relationships” explanation with the ability of some states to be better at providing public goods and redistributing wealth from the rich municipalities to the poor ones.
The public institutions hypothesis seems natural: if you have good politicians, they would write good laws which will support their population’s prosperity. Bad politicians would just be inept, or even corrupt. In this hypothesis, poor municipalities in rich (= well managed) regions should grow faster than poor municipalities in poor (= badly managed) regions. Our hypothesis, instead, proposes that poor municipalities with strong social connections to rich municipalities should grow faster than poor municipalities without such connections. For this we need to know two things: in which administrative region a municipality is (easy!) and to which social group of municipalities it belongs.
The latter is tricky, but not if you’re a data hoarder like yours truly. I had alreadyworked with phone call records in Colombia, so you might guess where this is going. I can represent Colombia as a network, where nodes are the municipalities. Municipalities are connected to other municipalities if there is a significant number of residents in the two municipalities that call each other. Once I have this network, I can perform community discovery and find groups of municipalities with tightly knit social relations.
Colombia’s social network at the municipality level. Click to enlarge.
Using data on the municipalities’ GDP (from DANE) and average wage (from PILA), we can now test whether convergence happens — i.e. growth is negatively correlated with starting level, the poorer you are the more you grow. This is false for administrative regions but true for social communities: there is a mildly significant (p < 0.05) negative relationship between a social group’s GDP (and average wage) growth and its initial level. Meaning: economic convergence happens at the social but not at the institutional level. I’d love an even lower p-value, but one can’t do much with such a low number of regions/groups (32 in Colombia).
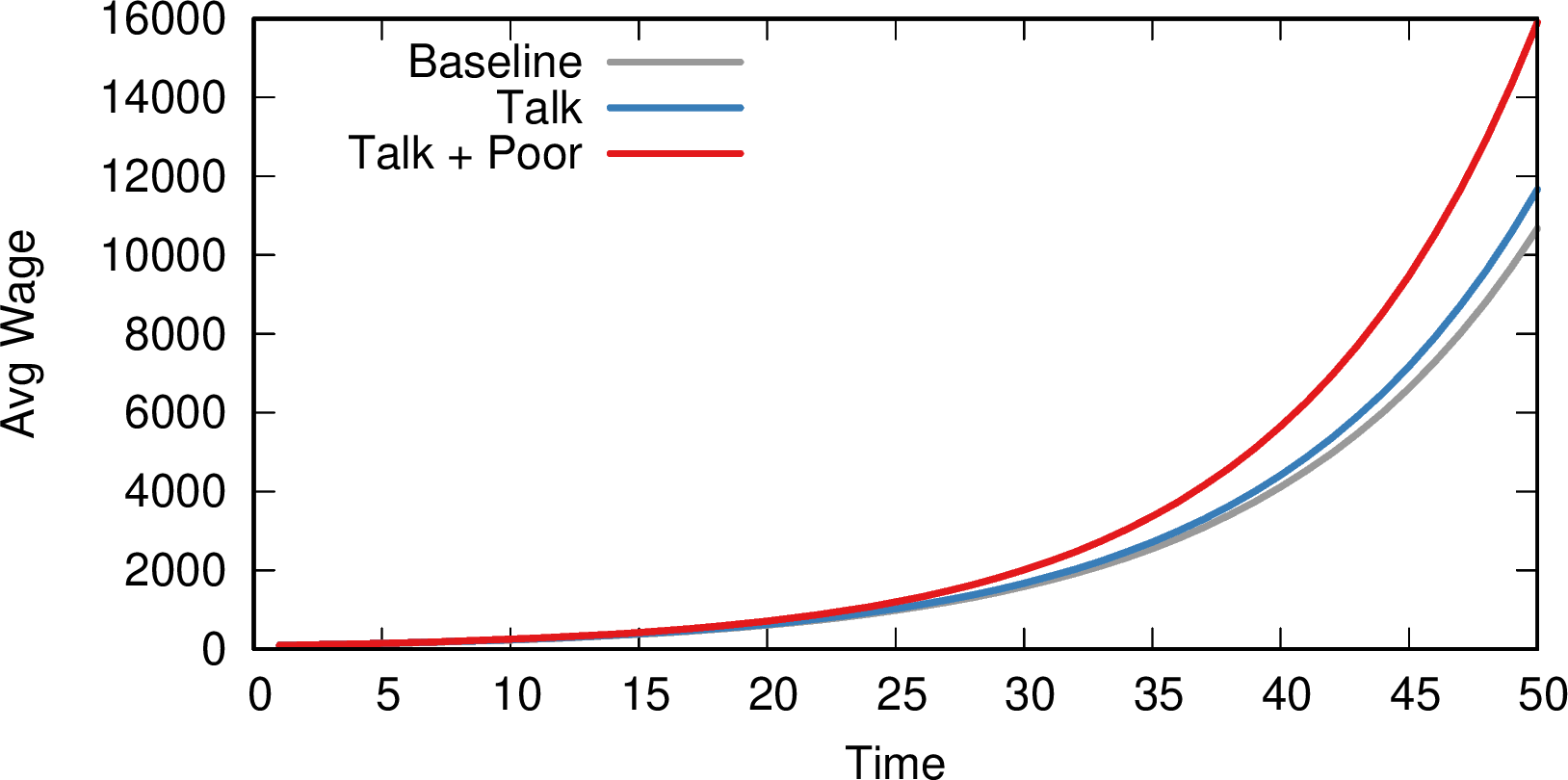
If social communities are converging, what could be driving the effect? We observe a robust (p < 0.01) positive relationship between the growth of per capita wages in a municipality and the average per capita wage in its social group. Meaning: if you talk to rich municipalities, you grow faster. Even the formality rate converges: if you talk with municipalities with low tax evasion, you start tax-evading less! Such relationships are absent for administrative regions, and survive a number of robustness checks — excluding the capital city Bogotá, excluding particularly small municipalities (in inhabitants, employees, or number of phone calls), using admin region fixed effects, etc. To get a sense of scale: suppose baseline growth is 1%. If you talk to a rich social group you’d grow, instead, by 1.02%. If you you talk to rich municipalities and you are also poor, you grow by 1.09% instead. This might not sound much, but it’s better to have it than not, and it stacks over time, as the picture below shows.
The effect of social relationships on average wage (y axis) over time (x axis). Gray = base growth; blue = growth while talking to rich social communities; red = talking to rich social community *and* being poor.
These results would be great in normal times, because they provide a possible roadmap to fostering economic convergence. One would have to identify places which lack the proper connections in the global knowledge network, and try to plug them in. The problem is that we’re not living in normal times. Lockdowns and quarantines due to the global pandemic have created gigantic obstacles to human mobility almost everywhere in the world. And, as I’ve shown previously, social relationships go hand in hand with mobility. For that reason, physical obstacles are also hampering the tightening of the global social network, one of the main highways of global development.
Don’t get me wrong: those are the correct measures and we should see them through. But we also should be mindful of their possible unintended side effects. Perhaps there are already enough people working on research on better medical devices, and on how to track and forecast outbreaks on the global social network. If this post has a moral, it’s to encourage people to find new ways to make the weaving of such global social network more robust to the black swan events that will follow COVID-19. Because they will happen, and our moral imperative of lifting people out of poverty can’t be the price we pay to survive them.