What is a “Community”?
The four of you who follow this blog regularly will know that I have a thing for something called “community discovery“. That’s because no matter how you call it, it always sounds damn cool. “Discovering Communities” or “Detecting the functional modules” or “Uncovering node clusters”. These are all names given to the task of finding groups of nodes in a network that are very similar to each other. And they make you feel like some kind of wizard. Adding to that, there are countless applications in epidemiology, sociology, immunology, marketing.
Far from being original, I share this passion with at least a thousand researchers. Being as smart as they are, they quickly realized that there are many ways in which you can group nodes based on their similarity. On the one hand, this is good news, as we basically have an algorithm for any possible community you want to find in your network. On the other hand, this made a lot of people freak out, as too many algorithms and too different solutions are usually a big red flag in computer science. A flag that says: “You have no idea what you are doing!” (although a computer scientist would put it in the cold and rational “Your problem is not formally defined”: it means the same).
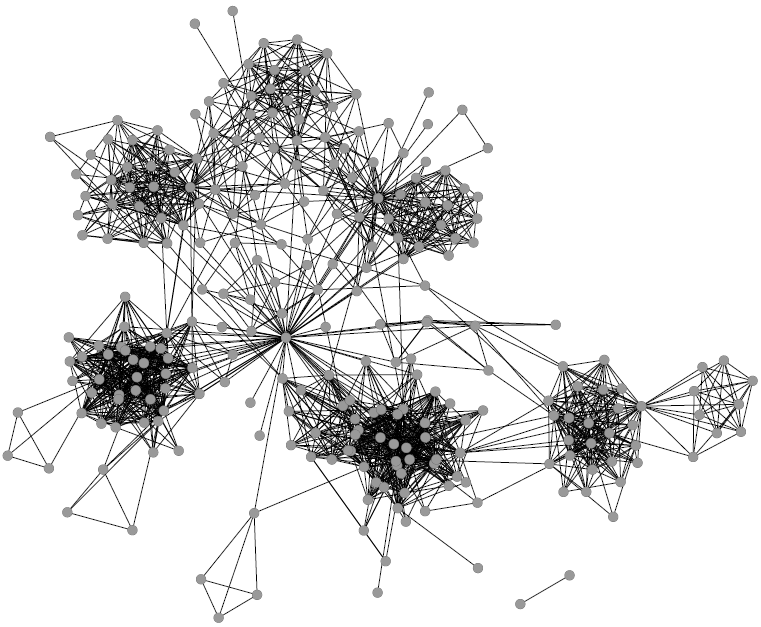
Yes, my signature “Community Discovery Picture” strikes again!
I personally think that the plus side is more predominant than the minus side, and you can get rid of the latter with a bit of work. Work that I have done with Dino Pedreschi and Fosca Giannotti in our paper “A classification for Community Discovery Methods in Complex Networks“. The trick is very simple. It just consists in noticing what’s wrong with the starting point. “Finding groups of nodes in a network that are very similar to each other”. Exactly what is “similar“? It is an umbrella term that can be interpreted in many different ways. After all, we already do this outside of network science. People can be very similar because they look alike. Or because they like the same things. So why can’t we just have different definitions of communities, based on how we intend similarity?
Well, because at the beginning of community discovery we thought that the problem was well defined. The first definition of community was something like: “A community is a group of nodes that are densely connected, and they have few edges connecting them to nodes outside the community”. Which is fine. In some cases. In others, we discovered that it doesn’t really make sense. For example, we discovered that many social networks have a pervasive overlap. It means that nodes are densely connected with many different groups, disproving the definition: now, the area outside the community could be just as dense as the community itself! And this is just one example: you take a hundred community discovery algorithms in literature and you’ll get a hundred different community results on the same network.
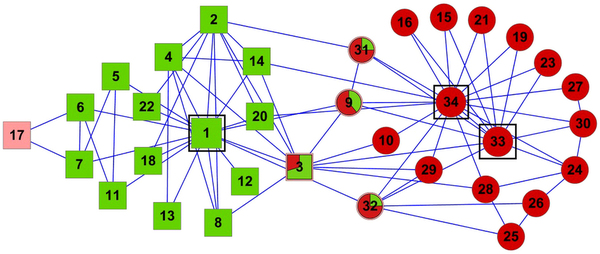
Overlap in the infamous Zachary Karate Club network, you can even win a prize if you mention it!
So now researchers in the community discovery… well… community were divided in three factions. We had those who thought that the problem was ill defined, thus everything done so far was just a royal mess. Then there were those who still thought that the problem was well defined, because their definition of community was the only one standing on solid ground and everybody else was just running around like a headless chicken. And then there were people like me and Sune Lehmann (whom I thank for the useful discussions). Our point was that there were many different definitions of communities, and the incompatible results are just the output of incompatible definitions of community.
This is the main take-away message of the paper. We then moved on and tried to actually spot and categorize all different community definitions (for 90s kids: think of a Pokédex for algorithms). Some choices were easy, some others weren’t. I personally think that more than an established classification, this is just a conversation starter. Also because the boundaries between community definitions are at least as fuzzy as the boundaries between the communities themselves. Algorithms in one category may also satisfy conditions imposed by another category. And to me that’s fine: I don’t really like to put things in separate boxes, I just want to have an insight about them.

I put tags, not classes.
So here you go, the classification we made includes the following “community types” (names are slightly changed from the paper, but it should be obvious which is which):
- Common Features: in this definition, each node has a number of attributes. If we are in a social network and the nodes are people, these attributes may well be the social connections, the movies you like, the songs you listen to. Communities are groups of nodes with similar attributes.
- Internal Density: the classical starting point of community discovery. Here we are interested in just maximizing the number of edges inside the communities.
- External Sparsity: a subtle variant of the Internal Density class. The focus of this definition is on considering communities as islands of nodes, not necessarily densely connected.
- Action Communities: this is a very dynamic definition of communities. Nodes are not just static entities, but they perform actions. Again, in a social network you not only like a particular artist: you listen to her songs. If your listening happens with the same, or similar, dynamics of other people, then you might as well form a community with them.
- Proximal Nodes: here we want the edges inside the communities to make it easy for a node to be connected to all other nodes in the community. Or: to get to any other node in the community I have to follow just a few edges.
- Fixed Structure: this is a very demanding community definition. It says that the algorithm knows what a community looks like and it just has to find that structure in the network.
- Link Communities: one of my favorites, because it revolutionizes the idea of community. Here we think that we need to group the edges, not the nodes. In a social network, we know different people for different reasons: family, work, free time, … The reason why you know somebody is the community. And you belong to many of them: to all the communities your edges belong to.
- Others: in any decent classification there must be a miscellaneous category! Some algorithms do not really follow a particular definition, whether because they just add features to other community discovery algorithms or because they let the user define their communities and then try to find them.
And now just a shortlist of readily available community discovery algorithms you can find on the Web:
- DEMON (by yours truly)
- HLC
- Infomap
- Label Propagation, Walktrap and Modularity Maximization (in the igraph library, either source code in C or for R or Python)
- BigClam (in the SNAP network library)
- k-Clique (in the Networkx Python package)
- CONGA/Peacock
- Edge Clustering
- PMM
- Fast Unfolding Modularity
- Conclude
That’s it! I hope I created a couple of new community discovery aficionados!
