How Quickly is COVID Really Spreading?
I don’t need to introduce to you what the corona virus is: COVID-19 has had a tremendous impact on everyone’s life in the past weeks and months. All of a sudden, our social media feeds have been invaded with new terminology: social distancing, R0, infection rate, exponential growth. Overnight, we turned ourselves into avid consumers of epidemics literature. We learned what the key to prevent the infection from becoming a larger problem is: slow the bugger down. That is why knowing how fast corona is actually moving is such a crucial piece of information. You have seen the pictures many times, they look something like this:
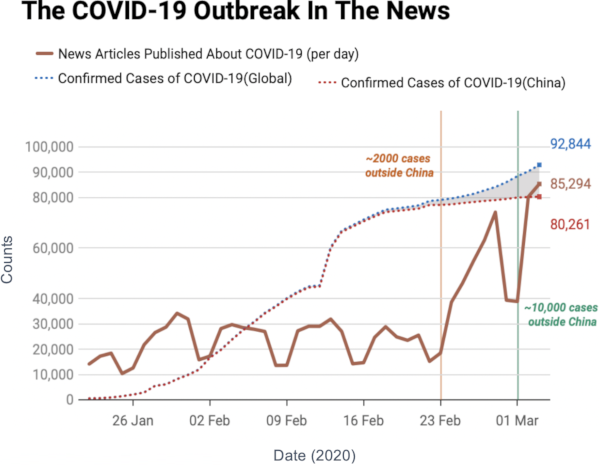
Image courtesy of my data science students: Astrid Machholm, Jacob Kristoffer Hessels, Marie-Louise Tommerup, Simon Breum, Zainab Ali Shaker Khudoir. If anything, it warms my heart knowing that, even during a pandemic, many journalists take their weekends off 🙂
What you’re seeing is the evolution in number of infected people — and how much non-infected people like me blabber about them online. Epidemiologists try to estimate the speed of infection by fitting the real data you see on an SI model. In it, people turn from Susceptible to Infected at a certain rate. These models are usually precise at estimating the number of infected over time, but they lack a key component: they assume that each individual is interchangeable and that anyone has a chance to be infected by anyone in their close proximity. In other words, they ignore the fact that we are embedded in a social network: some people are more central than others, and some have more friends than others.
To properly estimate how fast a disease moves, you need to take the network into account. And this is the focus of a paper of mine: “Generalized Euclidean Measure to Estimate Network Distances“. The paper has been accepted for publication at the 2020 ICWSM conference. The idea of the paper is to create a new measure that estimates the distance between the state of the disease at two moments in time, taking the underlying network topology into account.
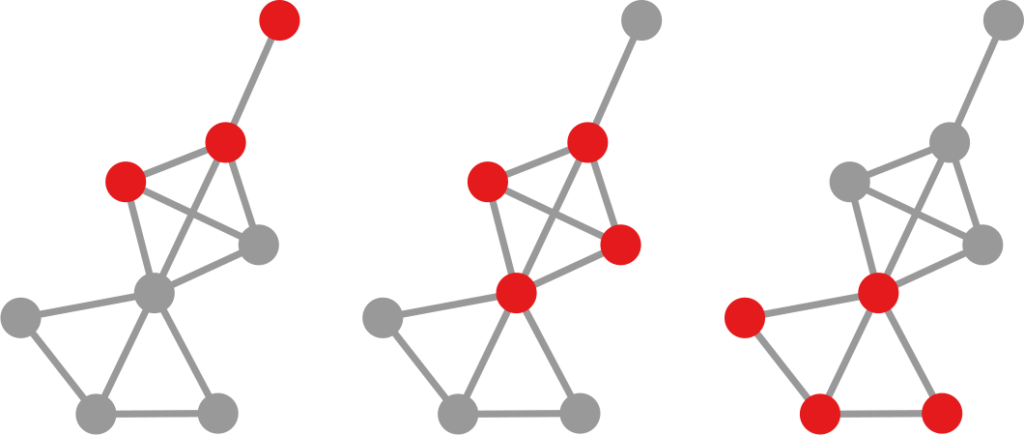
The question here is deceptively simple. Suppose you have a set of infected individuals. In the picture above, they are the nodes in red in the leftmost social network. After a while, some people recover, while others catch the disease. You might end up with the set of infected from the network in the middle, or the one in the right. In which case did the disease spread more quickly?
We have a clear intuitive answer: the rightmost network experienced a faster spread, because the infected nodes are farther from the original ones. We need to find a measure that matches this intuition. How do we normally estimate distances in the real world? We use a ruler: we draw a straight line between two points and we measure how long that line is. This is the Euclidean distance. Mathematically, that means representing the two points as vectors of coordinates (p and q), calculating their difference, and then using Pythagoras’ theorem to calculate the length of the straight line between them:
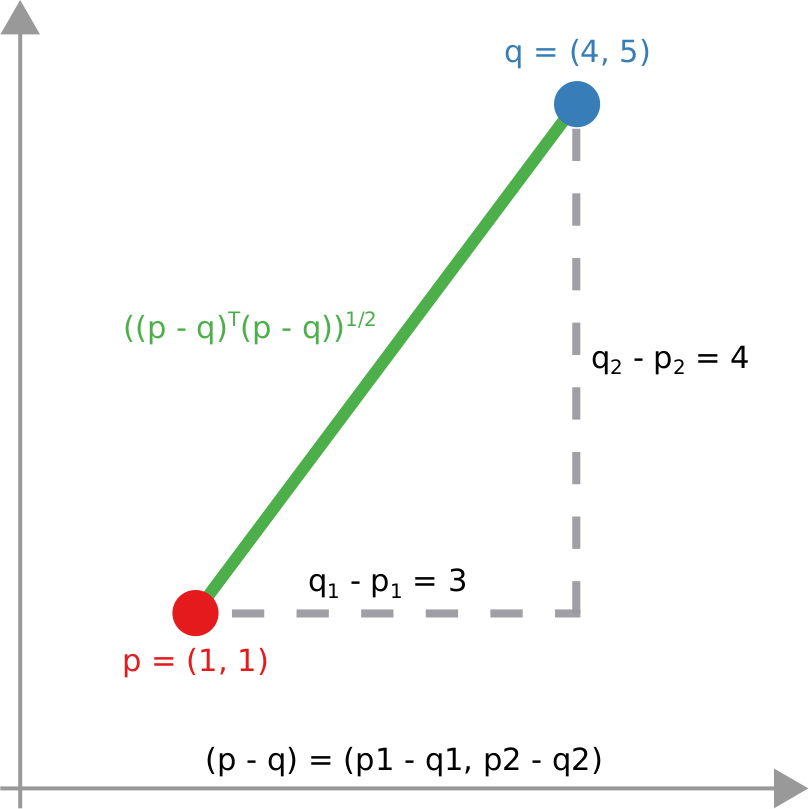
We cannot apply this directly to our network problem. This is because, for silly Euclid, every dimension has the same importance in estimating the distance between points. However, in our case, the points are the states of the disease. They do not live on the plane of Euclidean geometry, but on a network. Some moves in this network space are short and easy: moving between two connected nodes. But other moves are long and hard: between two nodes that are far apart. In other words, nodes that are connected to each other contribute less than unconnected nodes to the distance. The simplest example I can make is:

In the figure, each vector — for instance (1,0,0) — is the representation of the state of the disease of the graph beneath it: the entries equal to one identify the currently infected node. Clearly, the infection closer to the left graph is the middle one, not the right one. However, the Euclidean distance between the three vectors is the same: the square root of two. So how do we fix this problem? There is a distance measure that allows you to weigh dimensions differently. It is my favorite distance metric (yes, I am the kind of person who has a favorite distance metric): the Mahalanobis distance. Mahalanobis simply says that correlated variables should count less in estimating the distance: taller people tend to be heavier — because there’s more person to weigh — so we shouldn’t be surprised if someone taller than me is also heavier. But, if they weigh less, we would find it remarkable.
Now we’re just left with the problem of figuring out how to estimate, mathematically, what “correlated” means in a network. The paper has the full details. For here, suffice to say we augment Pythagoras’ theorem with the pseudoinverted graph Laplacian — a sentence I’m writing only to pretend I’m smart (it’s actually not sophisticated at all, and a super easy thing to calculate). The reason we use the graph Laplacian is because it is a standard instrument to estimate how fast things spread in a network.
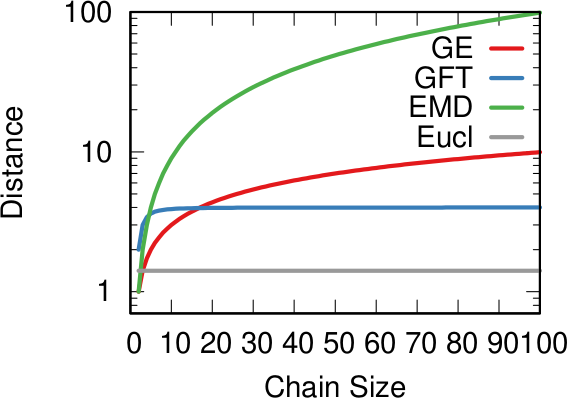
In the paper I run a bunch of tests to show that this measure matches our intuition. For instance, as shown above, if we have infected people at the endpoints of a chain graph, the longer the chain (x axis) the higher the estimated distance should be (y axis). GE (= Generalized Euclidean, in red) is my measure, and it behaves as it should: a constantly growing function (the actual values don’t really matter as long as they constantly grow as we move left to right). I compare the measure with few alternatives. The Euclidean (gray) obviously fails because it doesn’t know what a network is. EMD (green) is the Earth-Mover Distance, which is as good as my measure, but computationally more expensive. GFT (blue) is the Graph Fourier Transform, which is less sensitive to longer distances.
More topically, I can simulate different diseases with a SI model on a network. I can randomly change their infectiousness: how likely you (S) are to contract the disease if you’re in contact with an infected (I) individual. By looking at the beginning and at the end of an infection event, my measure can recover that infectiousness parameter, meaning it can distinguish between slow- and fast-moving diseases.
I’m obviously not pretending to be smarter than the thousands of epidemiologists that are doing a terrific job in fighting — and spreading awareness about — the disease. Their models at a global, national, and regional level for sure work extremely well and do not need this little paper of mine. However, this tool might find its use, when you have detailed data about a specific social network, for instance by using phone data to reconstruct a network of physical contacts. It also has a wider applicability to anything you can model as a diffusion process on a network, being a marketing campaign, the exploration of the Product Space by a country, or even computer vision. If you want to play with the code, I implemented a few network distance methods in a Python library.
