I am an associate prof at IT University of Copenhagen. I mainly work on algorithms for the analysis of complex networks, and on applying the extracted knowledge to a variety of problems.
My background is in Digital Humanities, i.e. the connection between the unstructured knowledge and the coldness of computer science.
I have a PhD in Computer Science, obtained in June 2012 at the University of Pisa. In the past, I visited Barabasi's CCNR at Northeastern University, and worked for 6 years at CID, Harvard University.
I am an associate prof at IT University of Copenhagen. I mainly work on algorithms for the analysis of complex networks, and on applying the extracted knowledge to a variety of problems.
My background is in Digital Humanities, i.e. the connection between the unstructured knowledge and the coldness of computer science.
I have a PhD in Computer Science, obtained in June 2012 at the University of Pisa. In the past, I visited Barabasi's CCNR at Northeastern University, and worked for 6 years at CID, Harvard University. The Social Network of Dante’s Inferno
Today I am going to commit one of the most hideous crimes in the research community. Today I am going to use my knowledge and expertise in my area to tell people in other areas what is a cool thing to do in their job. And I don’t even have the excuse of my age. Though you may say I was already crazy to begin with. My post is about putting some networky juice in literature studies and humanities. I am not the only one doing that – or to say that the complete segregation between humanities and science should not be there.
I already wrote a post about a network approach to the organization of classical archaeology literature. But maybe because of my computing humanities background, maybe because I always loved studying literature, I want to go deeper. So I reasoned about this a bit with my usual friends back in Italy and what came out is just a crazy thought. What if we try to create the idea for a network-based history of literature? That is to say: can we find in the network structure of pieces of literature art some traces of their meaning, of the relationships between them and their times, of the philosophy that moves them?

The first product coming out from this crazy idea was “The Social Network of Dante’s Inferno“, presented in the 2010 edition of the “Arts, Humanities and Complex Networks” symposium of NetSci and then published in a 2011 special issue of the Leonardo journal. In this work we were moved by the question: is a network of characters following some particular predictive patterns? If so: which ones?
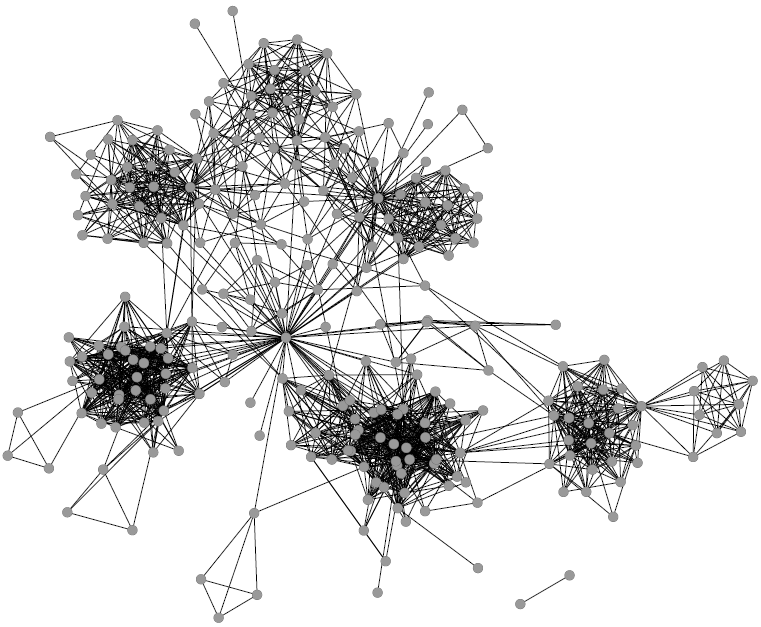
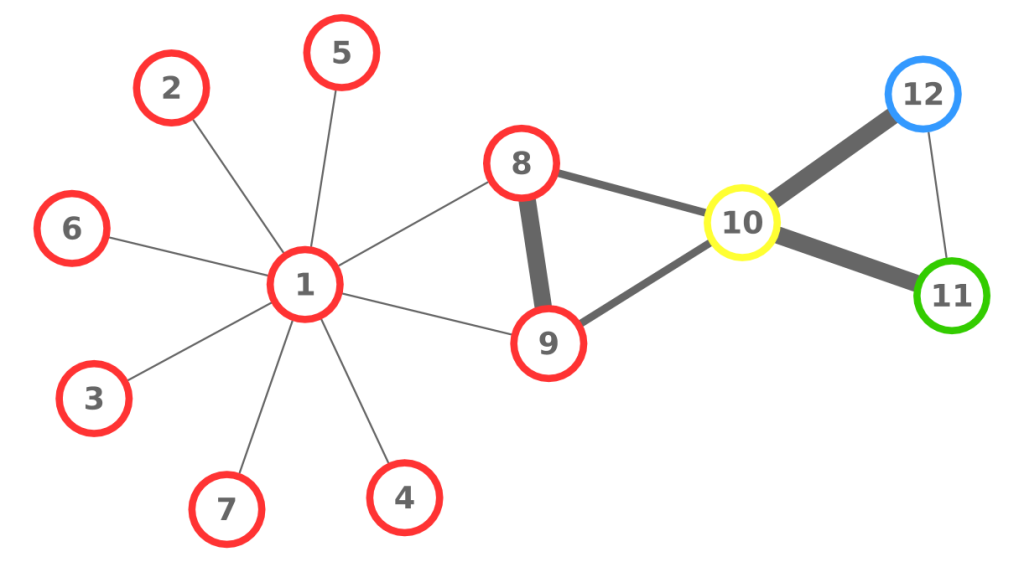
So we took a digital copy of Dante’s Inferno, where all interactions and characters were annotated with extra information (who the character was, if she was a historic or mythological figure, when she lived, …). We then considered each character as a node of the network. We created an edge between two characters if they had at least a direct exchange of words. Normal people would call this “a dialogue”. The result was pretty to see (click for a larger version):

The double-focus point of the Commedia emerges quite naturally, as Dante and Virgilio are the so-called “hubs” of the system. It is a nice textbook example of the rich-get-richer effect, a classic network result. But contrary to what the title of the paper says, we went beyond that. There are not only “social” relationships. Each character is also connected to all the information we have about her. There is another layer, a semantic one, where we have nodes such as “Guelph” or “Middle Ages”. These nodes enable us to browse the Commedia as a network of concepts that Dante wanted to connect in one way or another. One can ask some questions like “are Ghibelline characters preferably connected to historic or mythological characters?” or “what’s the centrality of political characters in the Inferno as opposed to the Purgatorio?” and create one’s own interpretation of the Commedia.
As fun as it was, we wanted to push this idea a bit beyond the simple “put a network there and see what happens”. That’s when Emmanuele Chersoni knocked on my door. He had manually annotated the Orlando Furioso (“The Frenzy of Orlando”) and the Gerusalemme Liberata (“Jerusalem Delivered”), two of the greatest masterpieces of the Italian epic poetry. This time it was the perfect occasion for a legendary artistic stand off.

To drive the theory a bit further, we asked ourselves: can we find in the network structure of a poem the principles of the poetics of the time and other factors influencing the authors? We knew that, in the century between the two poems, there was a transformation of the genre and significant historical and sociopolitical changes: a canonization of the genre took place, with more rigorous narrative structures and with the avoidance of the proliferation of plotlines. We wanted to see if these changes in the “rules of the game” could be rediscovered in the final product.
To test the hypothesis, we again created a character-character interaction network. We then grouped together characters with a community discovery algorithm (what else? 🙂 ). If the network is telling us something about the effects of this transformation of the genre, then the Gerusalemme Liberata should grow more organically, without many fluctuating sub-plots and a general collapse in the main plot at the end. And, surprise surprise, that’s exactly what we see. In the visualization below, we have a steamgraph where each color represents a community, its size proportional to the number of characters in it. And to me, the squiggly Orlando Furioso, with the central plot that becomes a giant at the end, seems not regular at all (click to enjoy the full resolution):
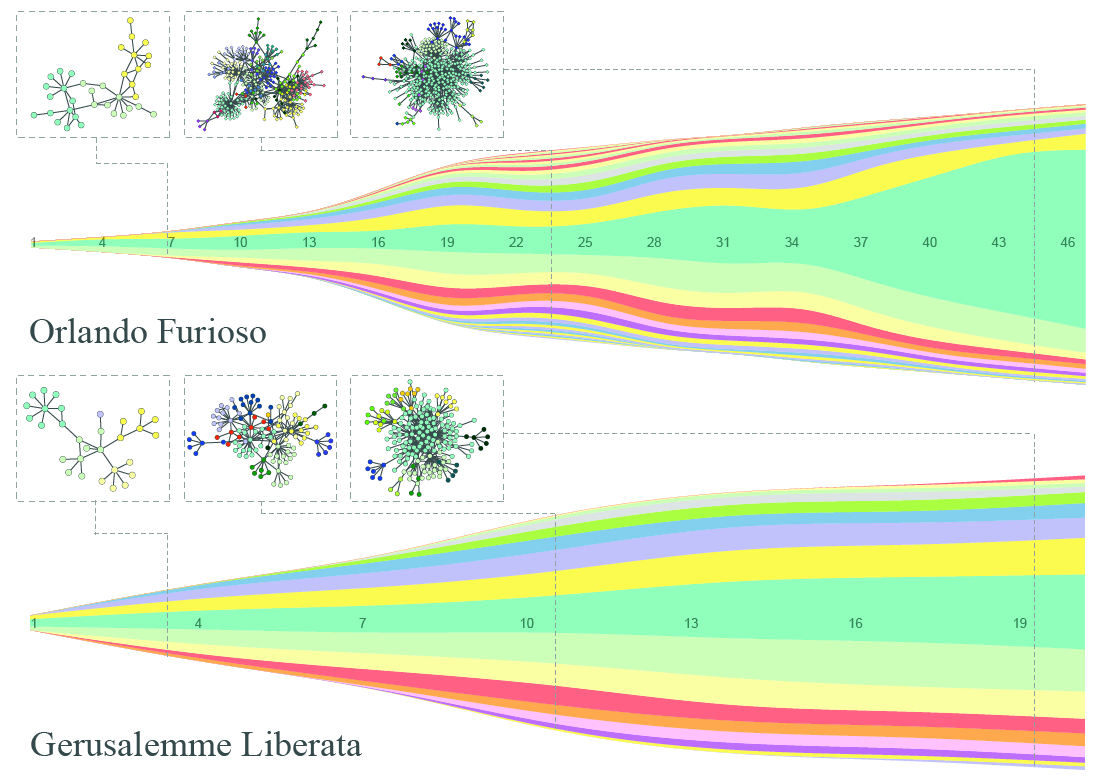
To conclude, let’s go back to the initial question. Why are we doing this? Because I feel that there is a fundamental flaw in the history of literature as it was taught to me. Rather than exclusively studying a handful of “significant works” per century, I’d want to also get a more wide knowledge about what were the fundamental characteristics of the art of the period. Network analysis can prove itself useful in this task. It “just” takes the effort of annotating many of these works, and then it can carry on the analysis in an almost automatic way. The result? To know what were the topical structures, theme connections, genre relations (yes, I go much further beyond what I showed, but I’m a dreamer). And how they gradually evolved over time. And who were the real authors who firstly used some topical structures. To me, it’s a lot, a goldmine, a kid-in-a-candy-store avalanche effect.